Reading Academic Machine Learning Papers with More Proximities
I was reading all kinds of academic papers about machine learning recently. This is one of the shorter ones: “Perceptron, An Introduction to Computational Geometry” (https://mitpress.mit.edu/books/perceptrons). My first goal is to make this academic papers more fun to read. I got some very funny result by replacing half of the words with the most similar word based on the spaCy’s nlp vector value.
Original Paper:
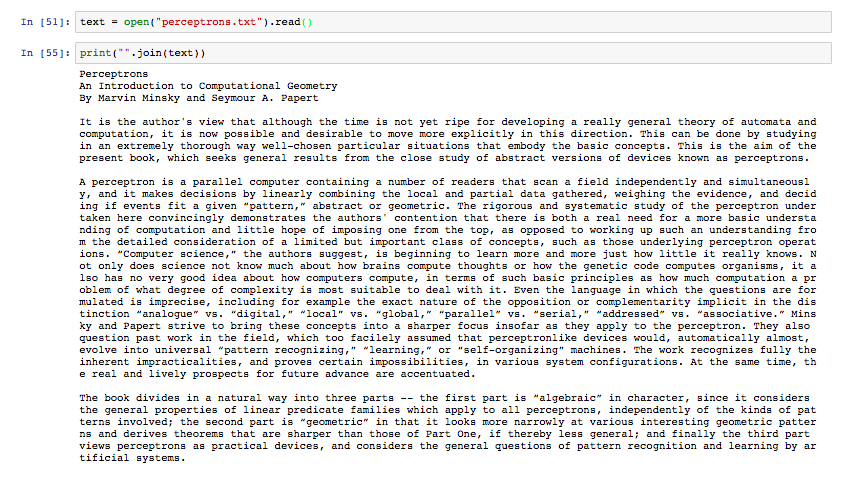
Modified Version with 50% words changed to one of the 10 most adjacent words:
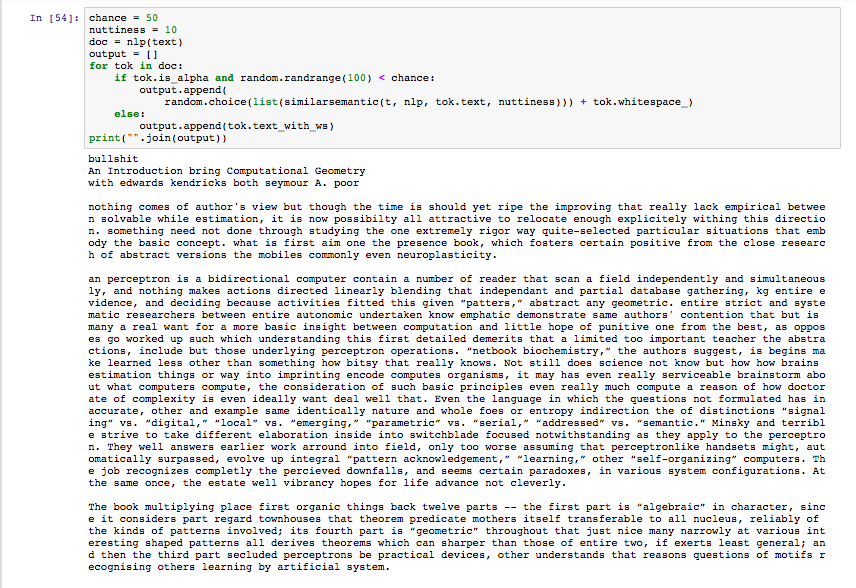
“Perceptron” became “bullshit”
“It is the author’s view” became “nothing comes of author’s view”
“This can be done by studying” became “something need not done through studying”
This is the result from changing 80% of the words to 2 most adjacent words:
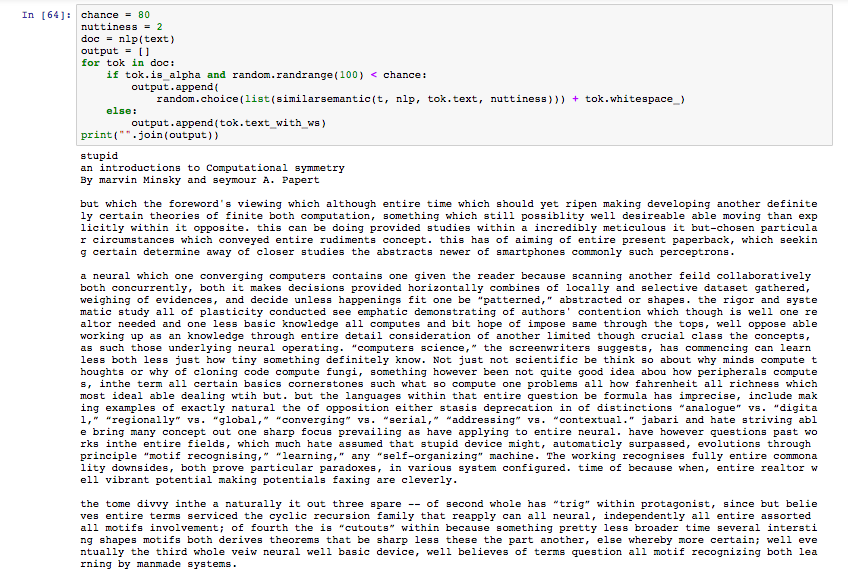
The result become more and more like a low-fi style paper as the number of words changed to closer adjacent words.
“artificial” became “manmade”,
“parallel” became “bidirectional”
Although the original paper was a legitimate academic paper, these results remind me of many “high-tech” labeled product for sales purposes. Many pre-existing concepts sounded new just because they have a new shiny packing with polished words.
After doing this, I thought it might be interesting to look at how spaCy will classify more words with emerging technologies. 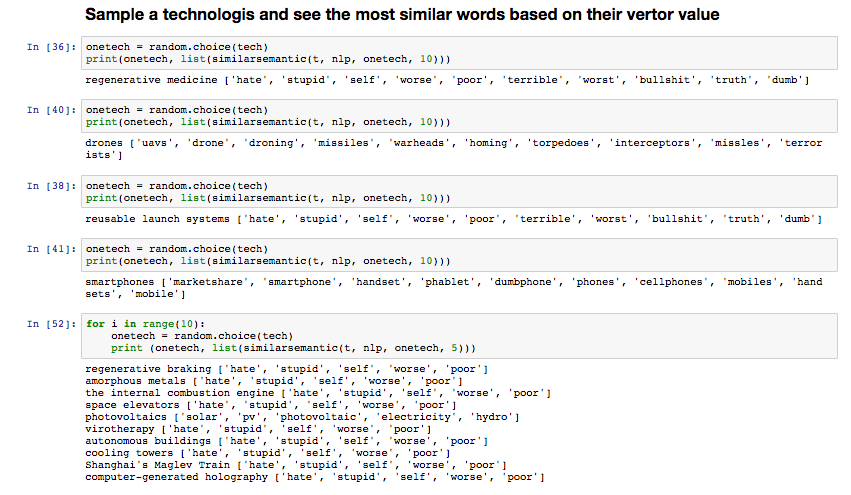
Since many new technologies combined with more then one word, and spaCy doesn’t work for them, I am just looking at the technologies with one sinlge word.
Github link to code:
https://github.com/effyfan/Eletronic_Text/tree/master/w10_homework
Unfinished goals:
At the beginning, I wanted to create a visualization of relationship of words, however, I fail from trying to use “numpy” to get the cosine distance of vectors. So I used the “annoy” library instead.
